Almost every organisation now carries a second version of itself inside its systems. A retailer reads demand through stock movement. A hospital depends on patient records. A bank studies transaction history. A marketing team follows campaign performance, customer behaviour, and audience segments.
When that data starts carrying gaps, duplicates, or old details, the effect shows up quickly. Reports become less reliable, forecasts lose direction, and teams make decisions with more doubt than they should.
Data quality management stops that drift. It gives organisations a disciplined way to keep data accurate, consistent, traceable, and usable across daily operations.
Data Quality Management for Decisions That Can Stand Scrutiny
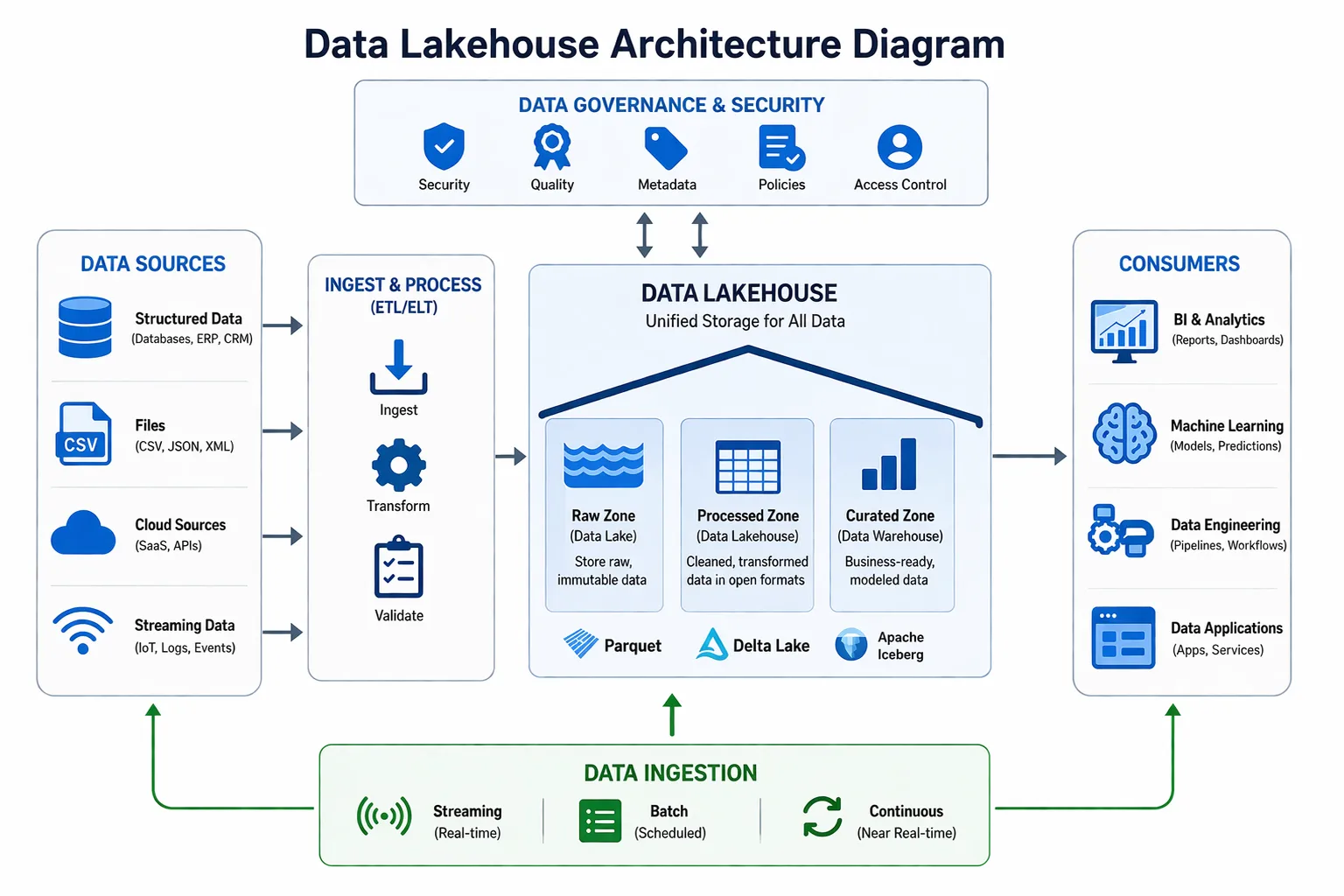
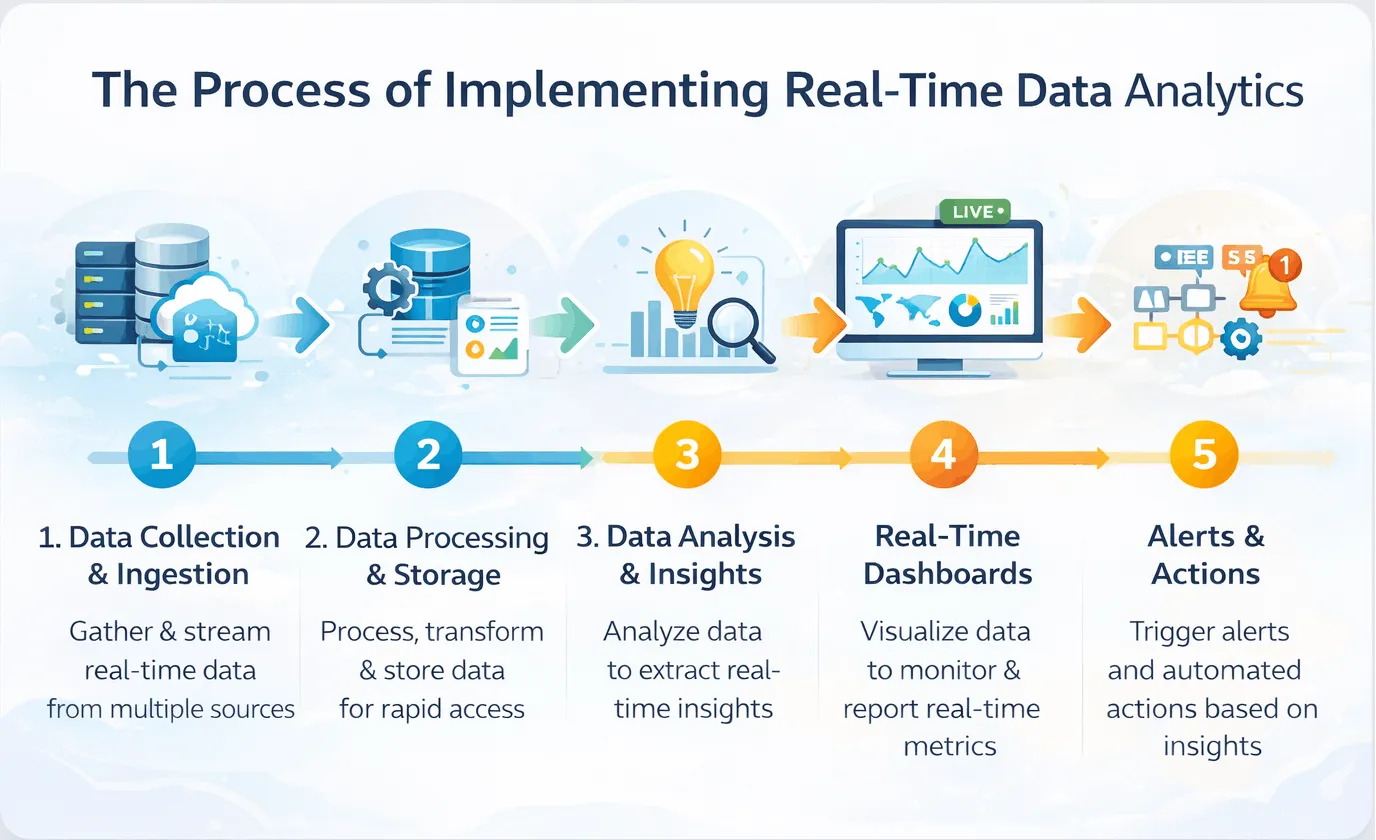
Data quality management is the operating discipline used to define, measure, monitor, improve, and protect data across its lifecycle.
In practice, it brings together profiling, validation, cleansing, metadata, lineage, stewardship, exception handling, and review cycles. A mature programme also sets acceptable thresholds, identifies critical data elements, assigns stewards, and defines what happens when quality drops below an agreed standard.
Simply put, data quality management prevents poor records from becoming accepted business truth. It protects campaign segments, revenue figures, and operational records from carrying hidden errors forward.
Strong data quality also depends on governance, because standards need authority before they can hold across teams. Quality checks then show whether those standards are working in practice.
Why Data Quality Is Important for Brands
Why is data quality important?
Because every brand experience is now shaped by information that customers rarely see.
A customer receives the same offer twice because two profiles exist in the CRM. A loyal buyer is excluded from a premium campaign because the purchase history was not updated. A sales team follows dead leads because the source data was never cleaned. A finance team delays reporting because revenue figures differ across systems.
These issues may start in systems, but they are felt in cost, speed, service, and customer perception.
The benefits of data quality management become visible when teams stop treating data correction as part of everyday work. Marketing targets with greater precision. Sales pipelines become easier to read. Finance closes with fewer reconciliation issues. Leadership works from a shared version of performance.
A Data Quality Framework Built for Real Operations
A data quality framework sets a clear process for judging data quality and correcting issues before they affect reports or decisions.
A useful framework should cover five areas.
1. Critical Data Identification
Start with the data that carries business weight. Customer records, transaction history, product data, consent fields, campaign performance, supplier records, and financial figures usually need priority.
These are the records where one wrong value can affect revenue, compliance, service, or reporting.
2. Business Rules and Quality Standards
Each important field needs a rule. An email field needs a valid format. A customer ID needs uniqueness. A consent value needs an approved status. Revenue should come from an agreed-upon source system.
Clear rules reduce interpretation. They also give technical teams something measurable to test.
3. Ownership and Stewardship
Data quality fails rapidly when everyone uses the data and nobody owns it.
Each domain needs an owner who can approve definitions, review exceptions, resolve conflicts, and define acceptable quality levels. This is where data governance consulting supports stronger policies, stewardship models, and accountability.
4. Monitoring and Incident Management
Quality needs regular monitoring through dashboards, alerts, and exception reports. The aim is to catch problems early enough to prevent wider operational or reporting damage.
A duplicate profile, missing field, or broken format should move into a clear issue queue with ownership, severity, and resolution timelines.
5. Root Cause Correction
Cleaning records is only part of the work. If errors continue to appear, the source needs attention.
The cause may sit inside a form, integration, migration, manual upload, CRM process, or unclear business rule. Fixing the source protects future data.
Data Quality Metrics Worth Tracking
Data quality metrics translate the condition of data into measurable evidence. They show which records are dependable, which processes are leaking errors, and where risk is building.
| Metric | What It Measures | Business Impact |
| Accuracy | Correctness of values against trusted sources | Reduces incorrect reports, offers, and customer records |
| Completeness | Presence of all required fields | Improves segmentation, compliance, and follow-up |
| Consistency | Alignment of values across systems | Clearer reporting and fewer cross-departmental conflicts |
| Timeliness | Freshness of data at the moment of use | Faster campaign, sales, and operational decisions |
| Uniqueness | Absence of duplicate records | Less repeated outreach and lower customer irritation |
| Validity | Conformance with approved formats and rules | Fewer workflow failures and processing errors |
| Integrity | Strength of relationships between connected records | More reliable reporting across linked data sets |
The strongest metrics are linked to a decision, workflow, or business risk. Measuring every field creates noise. Measuring the right fields gives teams control.

Data Quality Management Tools and Where They Fit
Data quality management tools support profiling, validation, standardisation, deduplication, anomaly detection, monitoring, and issue tracking.
The right tool depends on the organisation’s data maturity. A smaller team may need validation rules, duplicate checks, and alerting. A larger enterprise may need data lineage, metadata management, catalogues, stewardship workflows, and quality scorecards across multiple systems.
Technical teams may also use testing and observability tools inside data pipelines. These checks examine whether data arrives on time, matches expected patterns, and remains usable after transformation.
For pipeline-heavy environments, dataops consulting services can connect quality checks to delivery workflows. This allows issues to surface before they affect reports, models, or customer-facing systems.
Best Practices for Better Data Quality Management
Define Data in Business Language
A technically valid field can still confuse teams. “Active customer” should mean the same thing in sales, marketing, finance, and support.
Place Controls at Entry Points
Forms, APIs, manual uploads, migrations, and integrations are common points of failure. Early validation prevents errors from travelling across systems.
Use Data Contracts Between Teams
When one system sends data to another, both sides should agree on structure, format, frequency, and required fields. Data contracts reduce breakage when systems change.
Review Quality With Business Owners
Data teams can detect anomalies. Business owners can judge the impact. Both views are needed for useful remediation.
Treat AI and Analytics as Quality-Sensitive Systems
AI models, forecasts, and dashboards inherit the condition of the data they receive. Weak input can distort scoring, recommendations, targeting, and automated decisions.

FAQs
What is data quality management?
Data quality management is the discipline of controlling data accuracy, consistency, completeness, and usability across systems.
What is a data quality framework?
A data quality framework defines the rules, owners, metrics, tools, and workflows used to manage data quality.
Which data quality metrics should businesses track?
Accuracy, completeness, consistency, timeliness, uniqueness, validity, and integrity are the most useful data quality metrics.
Why is data quality important?
Data quality is important because poor data can affect reporting, compliance, customer experience, forecasting, and campaign performance.
What are data quality management tools?
Data quality management tools profile, validate, monitor, clean, standardise, and report issues across business data.
What are the benefits of data quality management?
The benefits include cleaner reporting, lower operational risk, stronger targeting, better compliance, and greater confidence in decisions.
How does data governance support data quality?
Data governance defines ownership, policies, and standards. Data quality checks whether those standards are followed in practice.