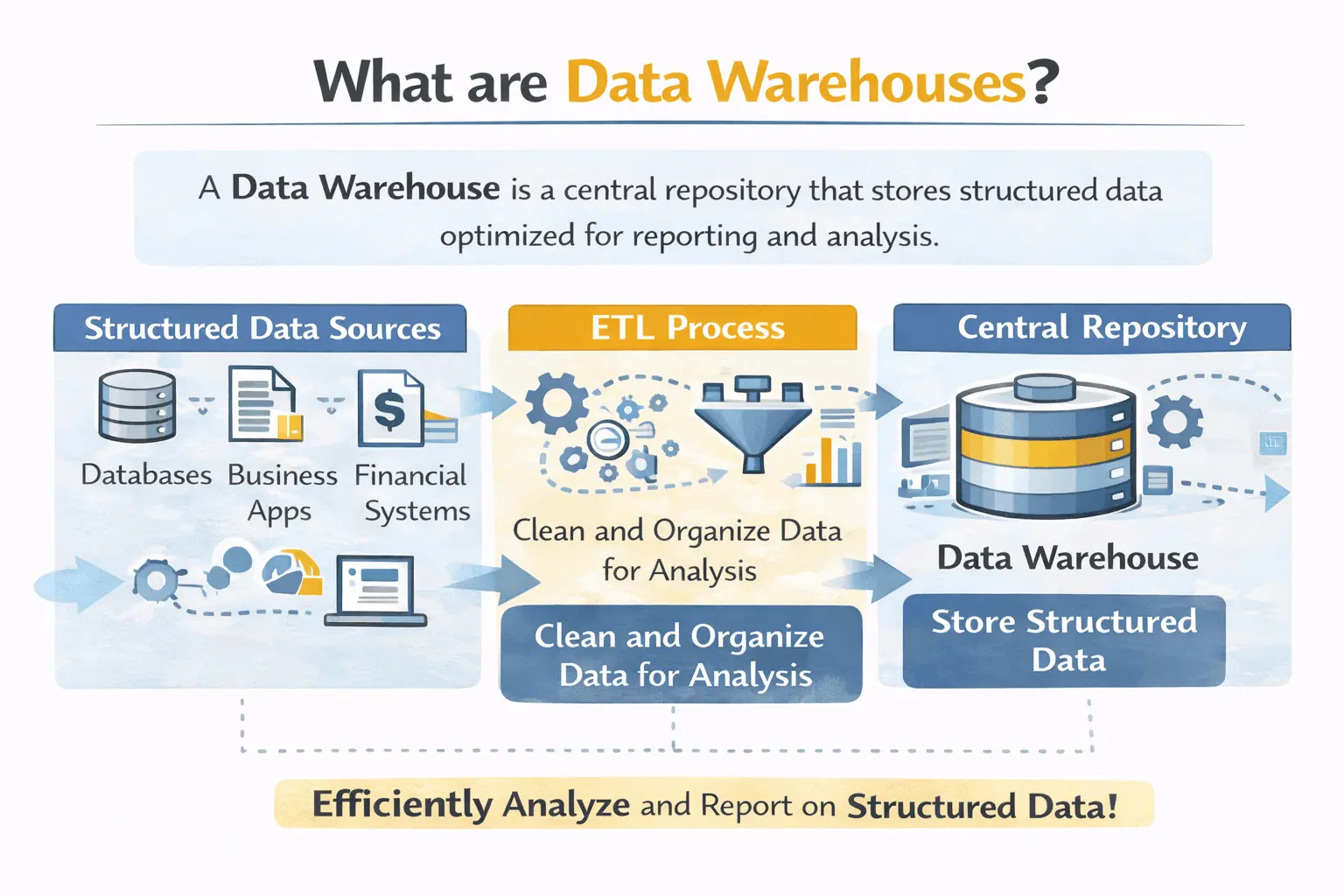
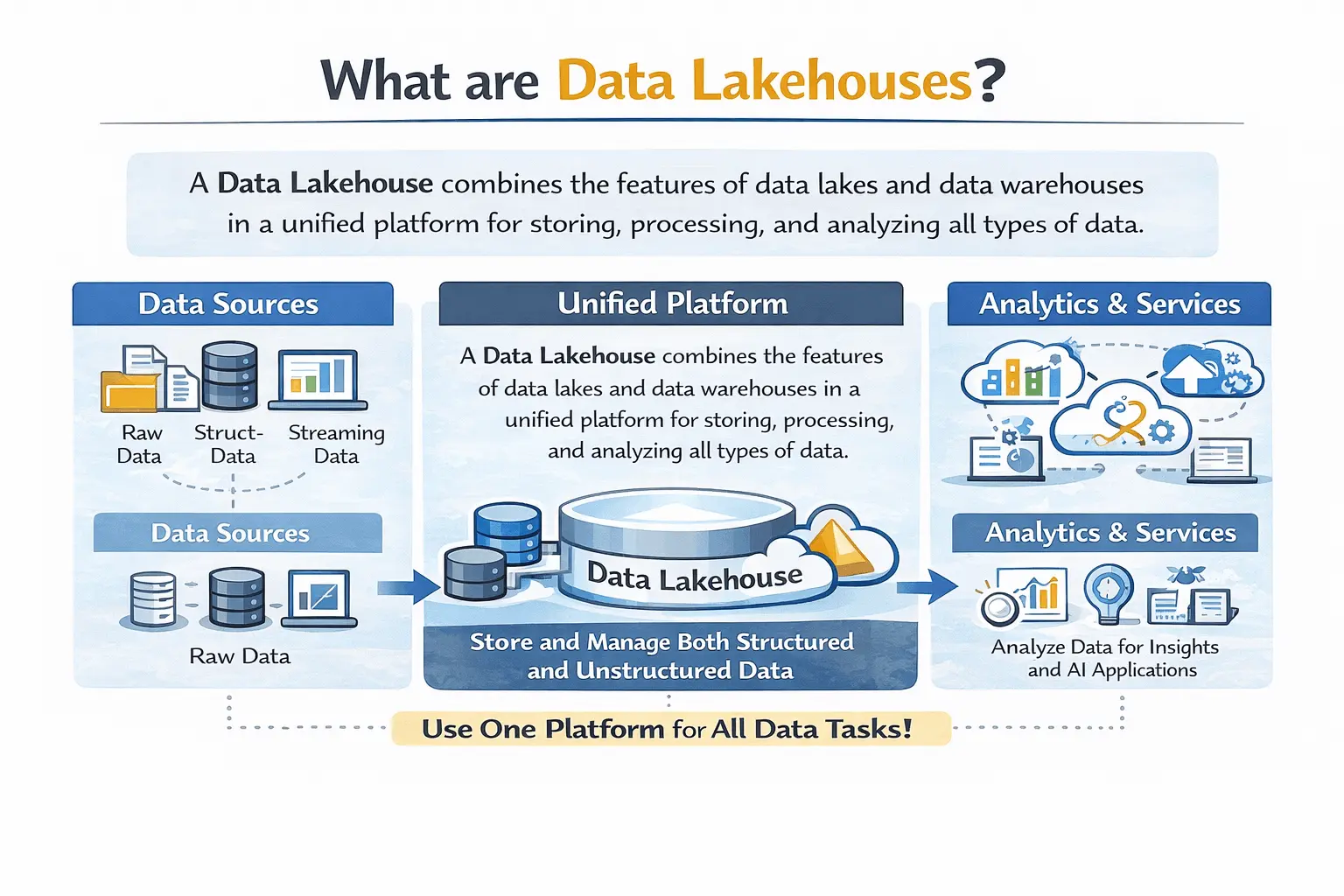
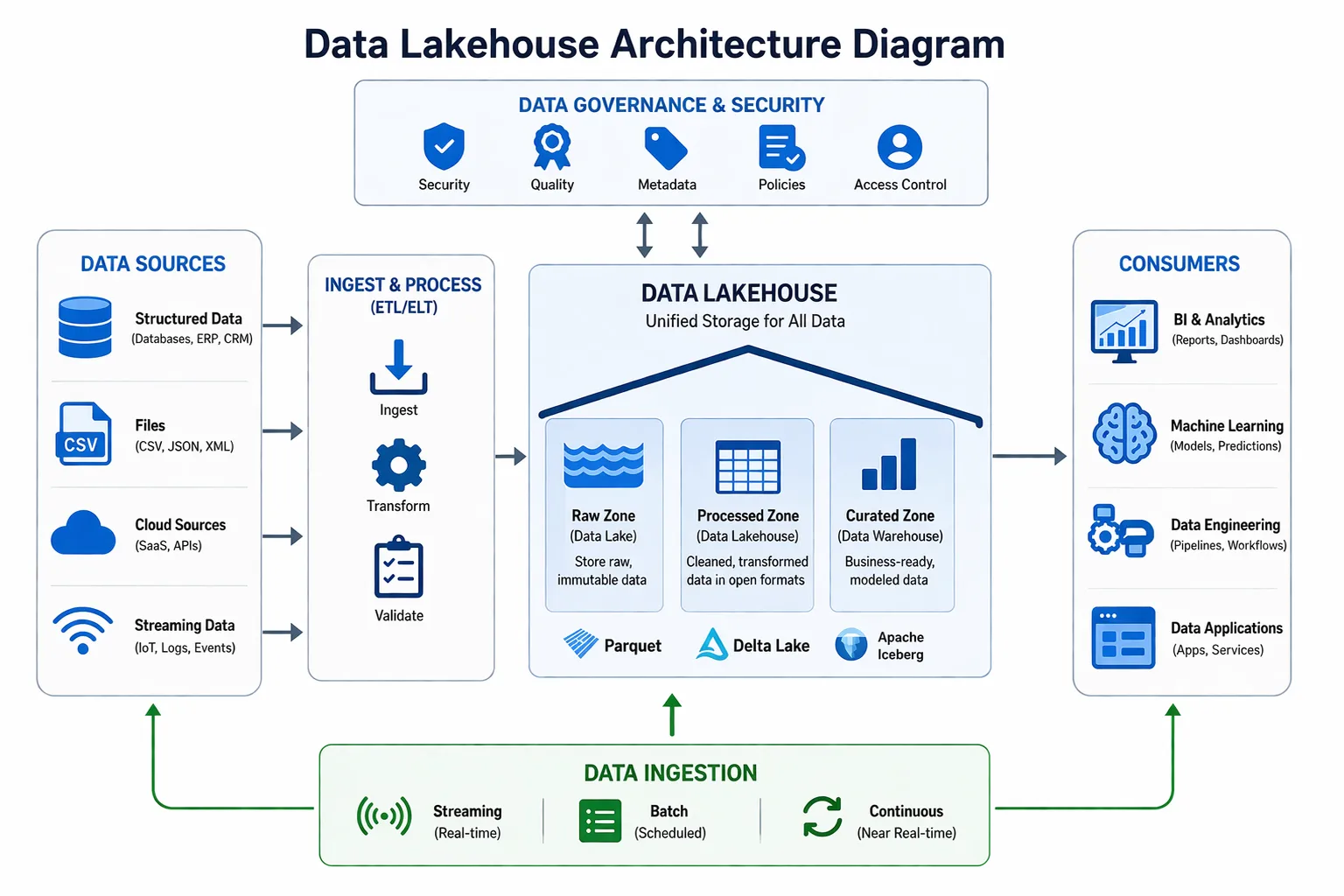
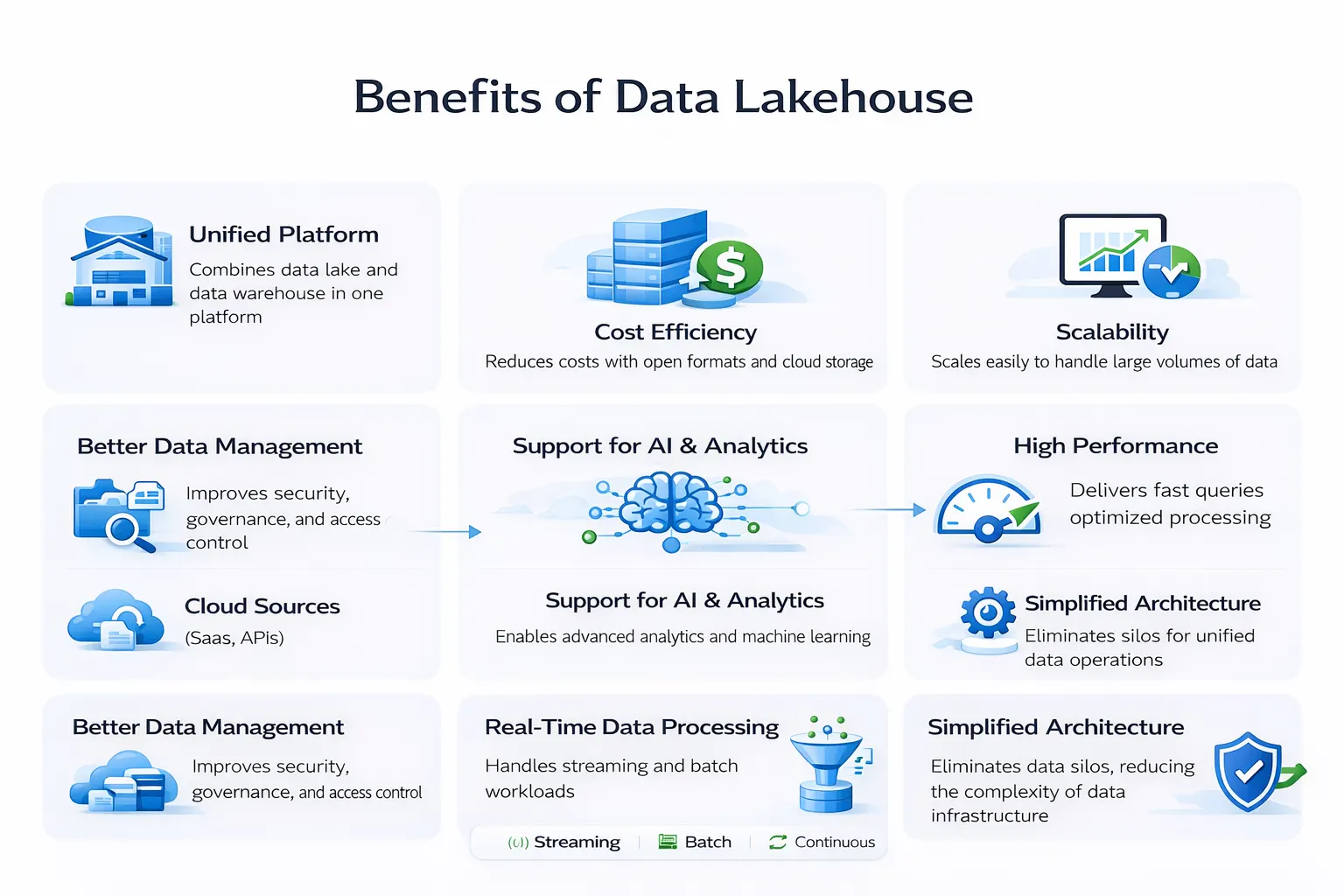
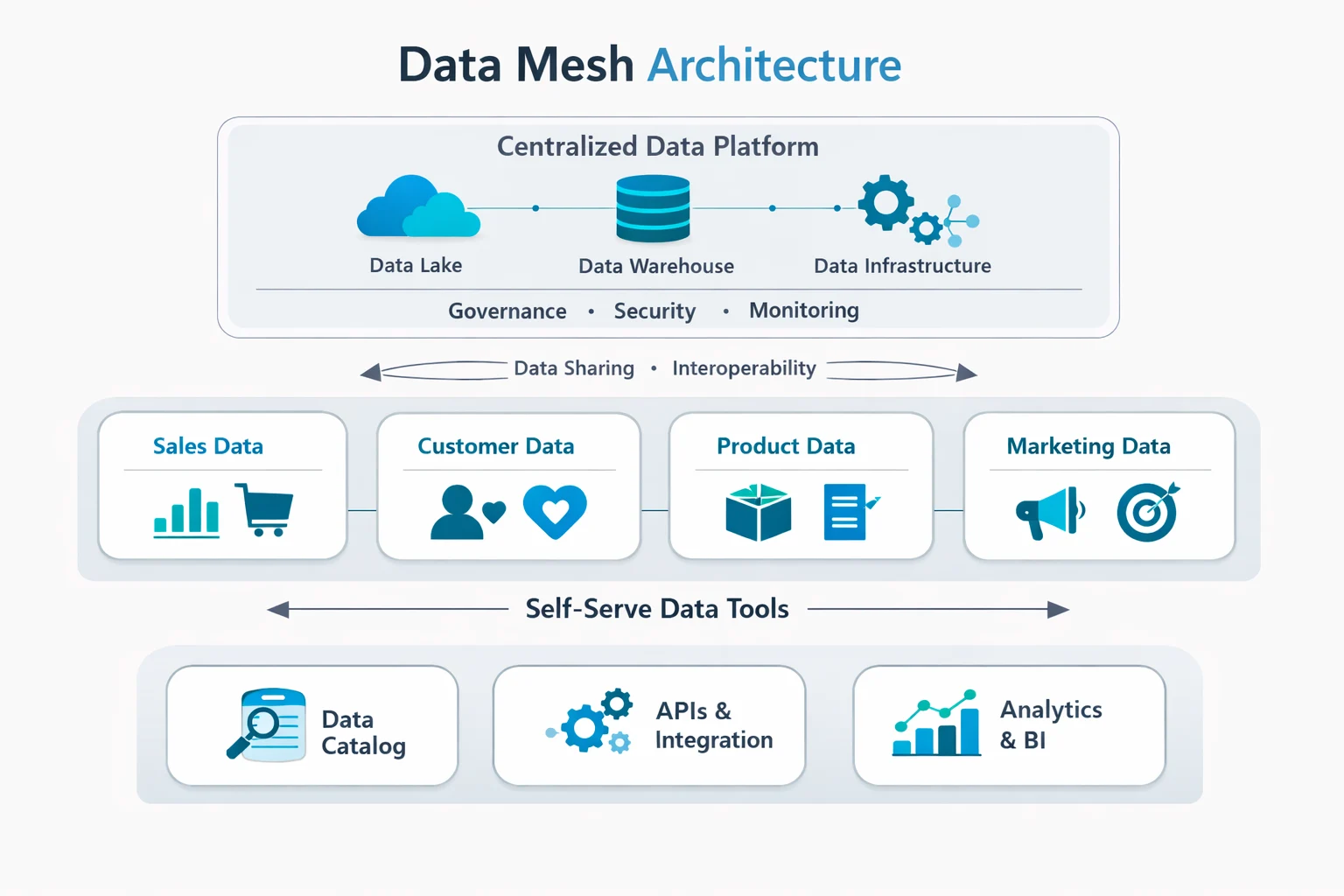
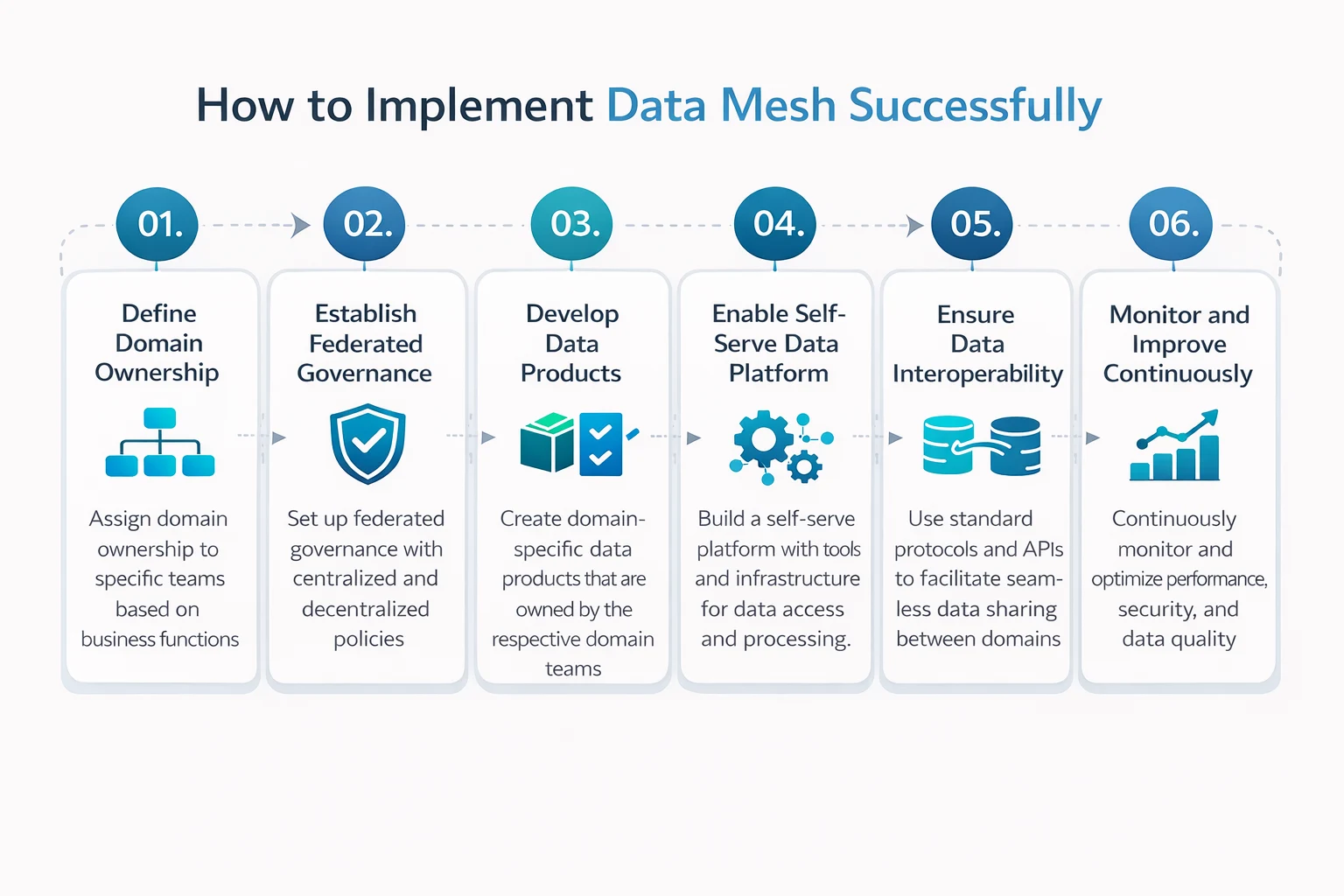
What I have noticed is that many companies these days are having similar issues when it comes to data. They have more data than ever. But they cannot trust it.
Reports contradict each other. Teams disagree on basic definitions. Sensitive information sits in systems nobody fully controls. That is not a data problem. That is a governance problem.
A data governance framework fixes this. It gives every team a shared system for managing data across tools, processes, and people. It covers who owns the data, who can access it, what quality standards apply, and how it stays accurate and secure.
In my experience, organizations that skip this step early spend twice as long fixing problems later. This article walks through the key components, real examples, and best practices to help you build one that actually works.
Here, we will explore the following:
- What is a data governance framework and how it works
- The key data governance framework components
- Data governance framework examples for startups and enterprises
- Data governance roles and responsibilities
- Cloud data governance framework essentials
- Data governance best practices for long-term success
What Is a Data Governance Framework?
A data governance framework is a set of rules, roles, and processes that controls how an organization handles its data.
It answers four core questions:
- Who owns the data?
- Who can access it?
- What quality standards apply?
- How is it kept accurate and secure?
Without a framework, different teams answer those questions differently. That creates the gaps that lead to bad reports, compliance failures, and wasted time.
The Core Ingredients That Make It Work
Decision rights, accountability, policies, and controls are the building blocks of any working framework.
The connection between these ingredients and daily operations is one of the crucial aspects of the data governance framework. It is not a one-time policy document. It is an operating system for how your organization handles data every day.
If your team needs expert support in getting this right, working with a data governance consulting partner can accelerate the process significantly.
Why Businesses Without a Data Governance Framework Keep Falling Behind
Here is what happens when governance is missing.
One department marks a customer as active. Another uses a completely different definition. Finance runs a report. Marketing runs the same report. The numbers do not match. Both teams lose an hour arguing about whose data is right.
That is something I have seen play out repeatedly across teams of every size.
Those small definition gaps create reporting errors, compliance risks, and time wastage that compound over months. Governance stops that by setting one shared standard across all departments.
For startups, that structure prevents chaos before the company scales. For larger organizations, an enterprise data governance framework brings together data across business units, platforms, and regions under one consistent model.
Following data governance best practices from the start is what separates companies that grow cleanly from those that spend years cleaning up old problems.
Key Data Governance Framework Components Every Organization Needs
The main data governance framework components stay fairly consistent regardless of company size.
Most frameworks include:
- Policies – Rules for how data is collected, stored, used, and shared
- Standards – Naming conventions, definitions, and formatting rules
- Ownership – Named individuals responsible for each data domain
- Stewardship – Day-to-day data quality and documentation support
- Security controls – Access permissions and protection measures
- Issue management – A process for resolving data quality problems
- Quality monitoring – Ongoing checks to keep data accurate and consistent
What Makes These Components Actually Work
Governance only works when it moves beyond documents.
A company needs real naming rules, documented definitions, and a reliable way to track where data comes from and how it changes. Strong frameworks link the data governance framework components to architecture, metadata, and quality controls rather than treating it as a policy exercise nobody reads.
If you need help mapping these to your specific business, feel free to Contact Us for a free consultation.

Data Governance Framework Examples That Actually Work
Looking at real data governance framework examples makes the concept far easier to apply.
The most widely used ones include:
| Framework | Best For | Approach |
| DAMA-DMBOK | Large enterprises | Comprehensive, process-heavy |
| DCAM | Financial services | Control and accountability-focused |
| COBIT | IT governance alignment | Risk and compliance driven |
| Data Governance Institute Model | Mid-size organizations | Flexible and adaptable |
| PwC Layered Framework | Multi-business unit companies | Central and domain-level balance |
The right model depends on the size and complexity of your business. This decision becomes especially important when teams go through a data migration process and need consistent governance standards bridging old and new systems.
Startup Example: Keep It Simple and Scalable
A startup does not need a full governance office on day one.
Start by identifying two or three key data areas. Customer data, billing data, and product usage are usually the right starting points. Assign one owner to each, document basic field definitions, and set access levels for anything sensitive.
Add a simple data classification policy so everyone knows what is public, internal, or restricted. That one step alone prevents a lot of expensive problems down the road.
Enterprise Example: Build for Scale and Compliance
An enterprise data governance framework has more layers because the business runs more systems, teams, and regulatory requirements at the same time.
A common model uses a central data management office, a governance council, and domain leaders across each department. This structure balances central standards with data integrity and local accountability at the same time.
In practice, the central office sets the standards. The council resolves cross-team conflicts. Domain leaders keep quality high in their own areas.
Data Governance Roles and Responsibilities: Who Does What
Clear data governance roles and responsibilities are what stop governance from being just a good idea nobody follows.
The Four Core Roles in Any Working Program
| Role | Responsibility |
| Executive Sponsor | Funds the program, provides authority at the leadership level |
| Data Owner | Makes business decisions for a specific data domain |
| Data Steward | Handles quality checks, documentation, and issue tracking |
| Governance Group | Resolves cross-functional conflicts, keeps standards aligned |
Most programs that actually work have all four roles clearly defined. When any role is missing or unclear, data problems pile up, and trust in the system drops fast.
Cloud Data Governance Framework: Governing Data Across Modern Platforms
A cloud data governance framework has become essential for most businesses today.
Data now moves across cloud apps, warehouses, and multi-platform environments constantly. Traditional on-premise governance policies do not stretch to cover that kind of movement.
Governance in the cloud must address:
- Access control across every connected platform
- Data movement and storage location rules
- Classification standards for cloud-native data
- Real-time monitoring and audit trails
A strong cloud data governance framework keeps teams agile while making sure data stays controlled, visible, and safe. Without it, cloud flexibility quickly turns into data sprawl that is very hard to untangle later.
Data Governance Best Practices That High-Trust Teams Follow
The data governance best practices that actually work are almost always the simple ones.
- Start with business goals, not technology choices
- Focus on the most critical data domains first and build outward from there
- Assign owners early before data problems start stacking up
- Write standards in plain language that any team member can follow
- Schedule quality reviews rather than waiting for something to break
- Treat governance as a living system, not a one-time setup project
Honestly, applying these data governance best practices consistently over time is what separates teams that trust their data from those that are always debating which number is correct.

FAQs
1. What is a data governance framework in simple terms?
A data governance framework is a set of rules, roles, and processes that controls how an organization manages its data. It defines who owns data, who can access it, what quality standards apply, and how it stays accurate and secure.
2. What are the main data governance framework components?
The core components include policies, standards, data ownership, stewardship, security controls, issue management, and quality monitoring. These building blocks work together to create accountability and consistency across the business.
3. What are some common data governance framework examples?
Widely used frameworks include DAMA-DMBOK, DCAM, COBIT, the Data Governance Institute model, and PwC’s layered framework. The right choice depends on your organization’s size, industry, and complexity.
4. What are data governance roles and responsibilities?
The main roles are executive sponsor, data owner, data steward, and governance group. Sponsors provide authority. Owners make decisions. Stewards handle quality and documentation. Governance groups resolve cross-functional issues.
5. Do startups need a data governance framework?
Yes, but a simple one. Start with three key data domains, one named owner per domain, basic access controls, and a simple data classification policy. That foundation scales cleanly as the business grows.
6. What is a cloud data governance framework?
A cloud data governance framework applies governance rules to cloud environments. It covers access control, data movement, storage locations, classification, and monitoring across cloud apps, data warehouses, and multi-platform systems.