
Own a data-centric business?
Then you must know how tough it is to choose between a data lake and a data warehouse.
Data lakes are a cheap way to store your data. But they can quickly turn messy.
Meanwhile, data warehouses are very fast and cleaner. But they can be very expensive and non-customizable.
So which one would you choose?
Neither, because there is an even better third option! It’s called a data lakehouse.
In this guide, I will help you understand what a data lakehouse is. I will also walk through the entire data lakehouse architecture.
Moreover, we will also discuss real-life data lakehouse examples.
Let’s first begin by understanding more about what a data lakehouse stands for.
What is a Data Lakehouse?
A data lakehouse is a modern data platform that combines the benefits of a data lake and data warehouse.
Let me explain it with this simple table:
| Traditional Data Lake | Traditional Data Warehouse | Data Lakehouse |
| Stores all raw data cheaply | Stores cleaned and structured data | Stores everything in one place |
| It can become messy and hard to use | Fast SQL queries and BI-ready | Fast queries + raw data flexibility |
| Great for data scientists | Great for business analysts | Great for everyone |
Data Lakehouse vs Data Warehouse vs Data Lake
For easier understanding, here is a detailed comparison between these three techniques:
| Feature | Data Lake | Data Warehouse | Data Lakehouse |
| Data types | Raw, unstructured, semi-structured | Structured only | All types supported |
| Schema approach | Schema-on-read (apply when reading) | Schema-on-write (apply before storing) | Both approaches work |
| Primary users | Data scientists, engineers | Business analysts | Everyone |
| Query performance | Slower, needs tuning | Very fast | Fast (warehouse-like) |
| Cost | Cheap storage | Expensive | Balanced |
| ACID transactions | Limited support | Full support | Full support |
Data Lakehouse Architecture
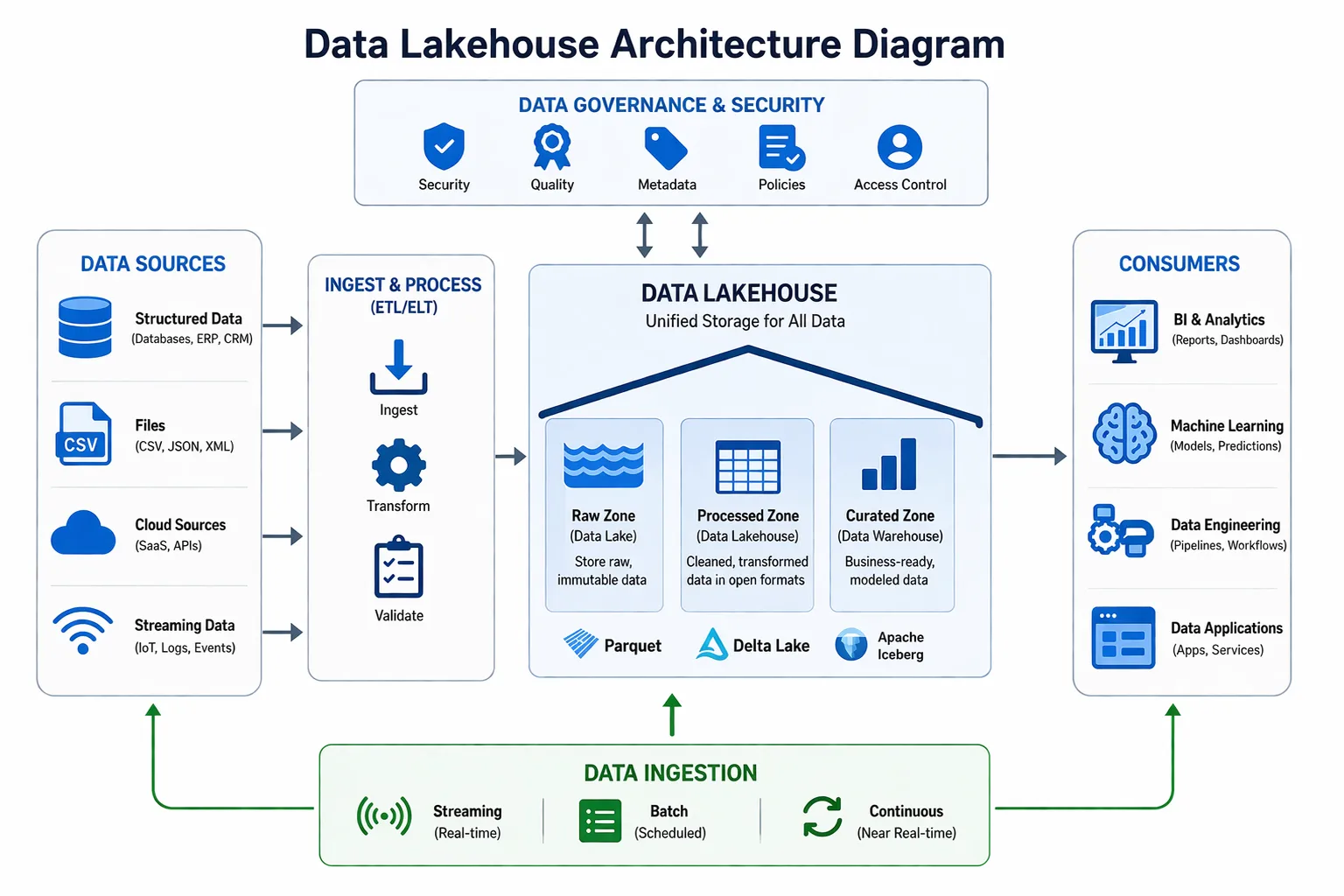
For a typical data lakehouse to work, you need several layers. These layers work together to store your data efficiently.
The five main key layers of this architecture include:
-
Ingestion
This layer brings data in from multiple sources.
Examples include Kafka and Lakeflow Connect.
-
Storage
To keep your raw and processed data in store, this layer is necessary.
It includes examples like S3 and ADLS.
-
Metadata & Catalog
Simply having your data stored is not enough.
It also needs to be organized and indexed. This is the layer that makes it all happen.
Examples include Unity Catalog and AWS Glue.
-
Processing
When you want to retrieve your data, it needs to be processed.
This is the layer that both transforms and queries your data. Examples include Spark and Photon Engine.
-
Serving
When the data is ready, this layer delivers it to the users.
Often, this layer is also used to provide insights to the users.
Common examples include BI tools and dashboards.
Key Data Lakehouse Benefits
Here are some of the benefits of a data lakehouse that can be very beneficial for your business:
| Benefit | What It Means for You |
| Lower costs | Only one storage system is required instead of two |
| Fresher data | Query data processed within minutes of arrival |
| Less duplication | No more copying data between the lake and the warehouse |
| One source of truth | Everyone works from the same data |
| Flexible for all users | Data scientists and business analysts can use the same platform |

Real-World Data Lakehouse Examples
Here are actual real-life scenarios of data lakehouses in action:
-
Hallmark
The greeting card company Hallmark modernized its data platform using a lakehouse.
As their data was becoming expensive to operate, this strategy helped them save money.
By rebuilding their data storage with Unity Catalog, they successfully reduced costs by 80%.
-
WeChat
The famous chat app WeChat migrated from a separate system to Lakehouse.
They used Apache Iceberg to reduce duplicated pipelines and data maintenance.
With the lakehouse platform for storage, they benefited from 65% storage savings.
-
Walmart
Walmart modernized its data lakes using Apache Hudi to implement a lakehouse architecture.
This enabled them to reduce data duplicates and streamline data availability.
Moreover, Apache Hudi also provided quick updates and projected changes.
Data Lakehouse Tools and Platforms
Here are the best platforms you can use to implement data lakehouse tools:
| Platform | Key Strengths |
| Databricks | Unity Catalog governance and Photon engine |
| AWS | SageMaker lakehouse and Iceberg support |
| Azure | ADLS storage and Azure Databricks integration |
| Open Source | Delta Lake and Apache Hudi table formats |
What are the Data Lakehouse Implementation Steps?
Here is how you can build your own data lakehouse:
- Choose the perfect storage layer, like Delta Lake or Iceberg
- Ensure you set up your ingestion using tools like Kafka
- Establish total governance by implementing a data access tool
- Connect your serving tools, like BI or SQL, for easy access

Conclusion
For any modern business, data lakehouse architecture provides a host of benefits.
As companies like Hallmark and WeChat have proven, they are reliable and efficient.
Alongside quicker data access, data lakehouses can also save you money.
So if you are tired of managing separate systems, it’s time to switch. Just use a data migration framework to move your data into a lakehouse.
Here is how you can make it happen.
Partner with Augmented Systems today and let us help make your business more efficient. This means implementing modern architectures, such as lakehouses, within your current setup.
Moreover, our team can help you get the perfect data strategy for your business. This lets you reap benefits at a lower cost.
Are you ready to unify your data? Contact Augmented Systems today for a free consultation!
FAQs
1. What is a data lakehouse in simple terms?
A data lakehouse combines the best of data lakes and data warehouses. It stores all your raw data cheaply like a lake, but lets you query it quickly like a warehouse. No more managing two separate systems.
2. What is the difference between a data lakehouse and a data warehouse?
The main data lakehouse vs data warehouse difference is flexibility. Data warehouses handle only structured data and require rigid schemas upfront. Data lakehouses handle all data types and support both fast SQL queries and data science workloads.
3. What does data lakehouse architecture look like?
Data lakehouse architecture has five layers: ingestion (bringing data in), storage (keeping raw and processed data), metadata (organizing everything), processing (transforming data), and serving (delivering insights). Open table formats like Delta Lake and Iceberg make it work.
4. What are the key data lakehouse benefits?
Data lakehouse benefits include lower costs (Hallmark saved nearly 80%), fresher data (queries within minutes), no data duplication, a single source of truth for everyone, and support for both SQL analytics and machine learning on the same platform.
5. What are popular data lakehouse tools?
Leading data lakehouse tools include Databricks (with Unity Catalog and Lakeflow Connect), AWS (SageMaker lakehouse), Azure (ADLS storage), and open table formats like Delta Lake, Apache Iceberg, and Apache Hudi for reliable data management.